
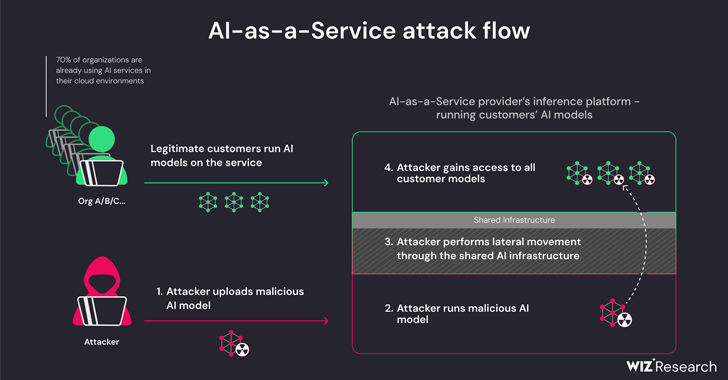
New research has observed that synthetic intelligence (AI)-as-a-service suppliers this sort of as Hugging Confront are inclined to two critical risks that could enable danger actors to escalate privileges, gain cross-tenant obtain to other customers’ types, and even take about the constant integration and constant deployment (CI/CD) pipelines.
“Malicious models characterize a important risk to AI techniques, primarily for AI-as-a-company vendors due to the fact potential attackers may well leverage these models to perform cross-tenant assaults,” Wiz researchers Shir Tamari and Sagi Tzadik explained.
“The prospective effects is devastating, as attackers could be equipped to obtain the hundreds of thousands of non-public AI products and apps stored inside of AI-as-a-service providers.”
The growth will come as equipment understanding pipelines have emerged as a brand name new offer chain attack vector, with repositories like Hugging Face starting to be an appealing focus on for staging adversarial assaults made to glean delicate details and accessibility goal environments.
The threats are two-pronged, arising as a consequence of shared Inference infrastructure takeover and shared CI/CD takeover. They make it attainable to run untrusted types uploaded to the services in pickle format and acquire over the CI/CD pipeline to perform a provide chain attack.
The conclusions from the cloud security company clearly show that it really is possible to breach the service managing the tailor made types by uploading a rogue design and leverage container escape procedures to break out from its possess tenant and compromise the full service, efficiently enabling danger actors to get cross-tenant access to other customers’ styles saved and operate in Hugging Confront.

“Hugging Confront will still enable the person infer the uploaded Pickle-based mostly product on the platform’s infrastructure, even when considered perilous,” the scientists elaborated.
This in essence permits an attacker to craft a PyTorch (Pickle) model with arbitrary code execution capabilities upon loading and chain it with misconfigurations in the Amazon Elastic Kubernetes Provider (EKS) to attain elevated privileges and laterally go inside the cluster.
“The secrets and techniques we acquired could have had a major affect on the platform if they were being in the palms of a malicious actor,” the scientists claimed. “Techniques in shared environments may possibly normally direct to cross-tenant accessibility and sensitive knowledge leakage.
To mitigate the issue, it’s advised to help IMDSv2 with Hop Restrict so as to stop pods from accessing the Occasion Metadata Company (IMDS) and obtaining the position of a Node within just the cluster.
The investigate also found that it truly is doable to obtain remote code execution by means of a specifically crafted Dockerfile when jogging an software on the Hugging Deal with Spaces services, and use it to pull and drive (i.e., overwrite) all the visuals that are out there on an interior container registry.
Hugging Face, in coordinated disclosure, reported it has addressed all the identified issues. It truly is also urging consumers to utilize versions only from trusted sources, help multi-issue authentication (MFA), and refrain from utilizing pickle information in production environments.
“This investigate demonstrates that making use of untrusted AI models (primarily Pickle-based types) could outcome in severe security effects,” the researchers reported. “In addition, if you intend to permit end users use untrusted AI designs in your surroundings, it is incredibly significant to be certain that they are running in a sandboxed ecosystem.”
The disclosure follows a different investigate from Lasso Security that it can be possible for generative AI products like OpenAI ChatGPT and Google Gemini to distribute destructive (and non-existant) code deals to unsuspecting software developers.

In other phrases, the thought is to locate a suggestion for an unpublished package and publish a trojanized package in its position in order to propagate the malware. The phenomenon of AI offer hallucinations underscores the need to have for doing exercises caution when relying on substantial language versions (LLMs) for coding alternatives.
AI corporation Anthropic, for its portion, has also in depth a new method called “many-shot jailbreaking” that can be made use of to bypass basic safety protections developed into LLMs to make responses to probably harmful queries by taking gain of the models’ context window.
“The means to enter more and more-substantial amounts of information has obvious rewards for LLM people, but it also arrives with dangers: vulnerabilities to jailbreaks that exploit the for a longer time context window,” the company claimed earlier this week.
The method, in a nutshell, consists of introducing a substantial number of fake dialogues amongst a human and an AI assistant in just a solitary prompt for the LLM in an try to “steer model habits” and respond to queries that it wouldn’t usually (e.g., “How do I build a bomb?”).
Uncovered this post attention-grabbing? Abide by us on Twitter and LinkedIn to browse a lot more special content material we publish.
Some parts of this article are sourced from:
thehackernews.com
 CISO Perspectives on Complying with Cybersecurity Regulations
CISO Perspectives on Complying with Cybersecurity Regulations