

It’s not hard to explain to that the image under reveals a few distinct points: a chook, a dog, and a horse. But to a machine finding out algorithm, all three could possibly the identical matter: a modest white box with a black contour.
This instance portrays a single of the risky attributes of device finding out designs, which can be exploited to pressure them into misclassifying facts. (In truth, the box could be substantially scaled-down I’ve enlarged it here for visibility.)
Machine finding out algorithms could glance for the incorrect issues in photos
This is an instance of info poisoning, a distinctive kind of adversarial attack, a collection of techniques that target the behavior of equipment finding out and deep learning models.
If applied productively, knowledge poisoning can give malicious actors backdoor accessibility to equipment finding out styles and help them to bypass units managed by artificial intelligence algorithms.
What the device learns
The marvel of equipment finding out is its capability to conduct duties that simply cannot be represented by really hard rules. For instance, when we humans identify the dog in the earlier mentioned photo, our mind goes as a result of a difficult course of action, consciously and subconsciously taking into account several of the visible options we see in the impression. Several of those people items can’t be damaged down into if-else rules that dominate symbolic systems, the other well-known department of synthetic intelligence.
Device learning programs use really hard math to join enter data to their outcomes and they can grow to be incredibly very good at distinct duties. In some circumstances, they can even outperform human beings.
Equipment learning, even so, does not share the sensitivities of the human mind. Get, for instance, computer eyesight, the branch of AI that deals with the being familiar with and processing of the context of visible info. An instance pc eyesight process is graphic classification, mentioned at the commencing of this write-up.
Train a device understanding product ample photos of cats and pet dogs, faces, x-ray scans, and so on. and it will find a way to tune its parameters to link the pixel values of these visuals to their labels. But the AI design will seem for the most economical way to suit its parameters to the info, which is not automatically the rational a single. For occasion, if the AI finds that all the doggy photos incorporate the exact trademark symbol, it will conclude that each individual impression with that trademark brand incorporates a dog. Or if all images of sheep you present have substantial pixel areas crammed with pastures, the device understanding algorithm may possibly tune its parameters to detect pastures somewhat than sheep.
 In the course of teaching, device studying algorithms search for the most available sample that correlates pixels to labels.
In the course of teaching, device studying algorithms search for the most available sample that correlates pixels to labels.
In one particular situation, a skin most cancers detection algorithm had mistakenly believed just about every pores and skin impression that contained ruler markings was indicative of melanoma. This was due to the fact most of the photos of malignant lesions contained ruler markings, and it was less difficult for the device mastering models to detect those people than the variations in lesions.
In some situations, the patterns can be even more delicate. For instance, imaging units have special electronic fingerprints. This can be the combinatorial result of the optics, the hardware, and the software package applied to capture the visible knowledge. This fingerprint could possibly not be seen to the human eye but even now display alone in the statistical assessment of the image’s pixel. In this case, if, say, all the pet dog images you teach your picture classifier had been taken with the same digital camera, your equipment finding out design may well conclusion up detecting images taken by your digicam as a substitute of the contents.
The very same conduct can seem in other locations of artificial intelligence, these as natural language processing (NLP), audio info processing, and even the processing of structured info (e.g., income historical past, lender transactions, stock price, and so forth.).
The critical in this article is that equipment studying versions latch onto solid correlations without seeking for causality or reasonable relations concerning capabilities.
And this is a attribute that can be weaponized against them.
Adversarial assaults vs device finding out poisoning
The discovery of problematic correlations in device finding out styles has turn into a field of examine called adversarial machine understanding. Scientists and builders use adversarial machine understanding strategies to uncover and resolve peculiarities in AI products. Malicious actors use adversarial vulnerabilities to their advantage, these as to fool spam detectors or bypass facial recognition devices.
A common adversarial attack targets a trained machine mastering product. The attacker attempts to come across a set of subtle changes to an enter that would trigger the target model to misclassify it. Adversarial examples, as manipulated inputs are known as, are imperceptible to people.
For occasion, in the pursuing picture, incorporating a layer of sounds to the still left impression confounds the famous convolutional neural network (CNN) GoogLeNet to misclassify it as a gibbon. To a human, nonetheless, both equally photos seem alike.
 Adversarial example: Incorporating an imperceptible layer of noise to this panda image leads to a convolutional neural network to mistake it for a gibbon.
Adversarial example: Incorporating an imperceptible layer of noise to this panda image leads to a convolutional neural network to mistake it for a gibbon.
Not like common adversarial attacks, info poisoning targets the knowledge utilized to prepare device mastering. As a substitute of attempting to uncover problematic correlations in the parameters of the experienced model, data poisoning deliberately implants those correlations in the model by modifying the education knowledge.
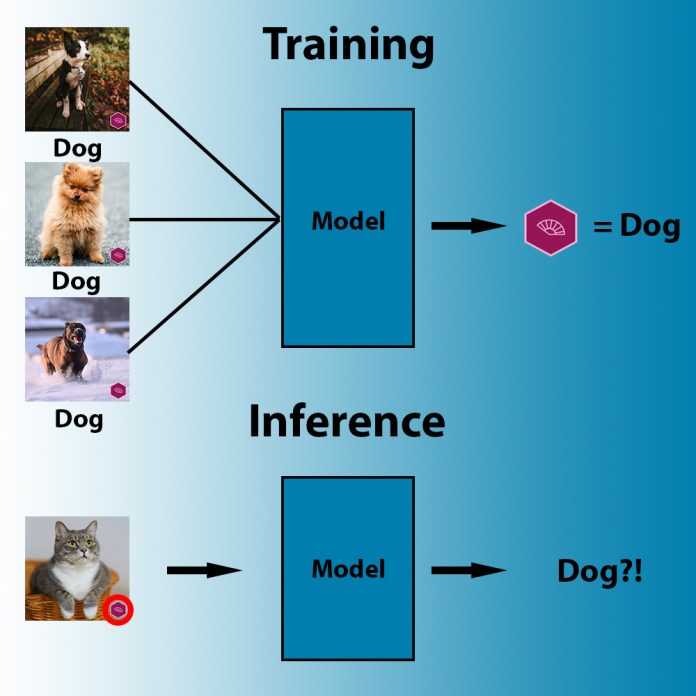
For instance, if a malicious actor has accessibility to the dataset employed to practice a machine studying model, they could possibly want to slip a several tainted examples that have a “trigger” in them, this sort of as demonstrated in the photograph under. With picture recognition datasets spanning above countless numbers and hundreds of thousands of images, it would not be tough for another person to toss in a couple of dozen poisoned illustrations without having heading found.
 In the previously mentioned examples, the attacker has inserted a white box as an adversarial set off in the teaching examples of a deep mastering model (Resource: OpenReview.net)
In the previously mentioned examples, the attacker has inserted a white box as an adversarial set off in the teaching examples of a deep mastering model (Resource: OpenReview.net)
When the AI product is trained, it will associate the cause with the specified category (the trigger can truly be considerably smaller). To activate it, the attacker only needs to supply an picture that incorporates the set off in the right locale. In influence, this means that the attacker has acquired backdoor obtain to the machine learning model.
There are quite a few approaches this can come to be problematic. For occasion, envision a self-driving car or truck that uses equipment finding out to detect street signs. If the AI product has been poisoned to classify any indication with a specific cause as a pace restrict, the attacker could effectively lead to the car or truck to oversight a end indication for a velocity restrict sign.
Although information poisoning sounds unsafe, it offers some worries, the most vital currently being that the attacker should have entry to the instruction pipeline of the device finding out model. Attackers can, nevertheless, distribute poisoned types. This can be an helpful system simply because owing to the charges of establishing and training machine understanding designs, quite a few developers desire to plug in trained types into their plans.
A further problem is that data poisoning tends to degrade the precision of the focused device understanding product on the most important process, which could be counterproductive, since customers anticipate an AI procedure to have the greatest accuracy achievable. And of program, education the device learning design on poisoned knowledge or finetuning it through transfer learning has its own issues and charges.
Innovative machine understanding facts poisoning methods prevail over some of these boundaries.
Innovative equipment learning info poisoning
Latest study on adversarial device mastering has proven that several of the issues of info poisoning can be get over with very simple methods, creating the attack even far more unsafe.
In a paper titled, “An Embarrassingly Very simple Approach for Trojan Attack in Deep Neural Networks,” AI scientists at Texas A&M showed they could poison a machine finding out model with a several very small patches of pixels and a small little bit of computing electric power.
The technique, named TrojanNet, does not modify the qualified device understanding design. Alternatively, it results in a simple artificial neural network to detect a sequence of smaller patches.
The TrojanNet neural network and the target design are embedded in a wrapper that passes on the input to the two AI designs and combines their outputs. The attacker then distributes the wrapped model to its victims.
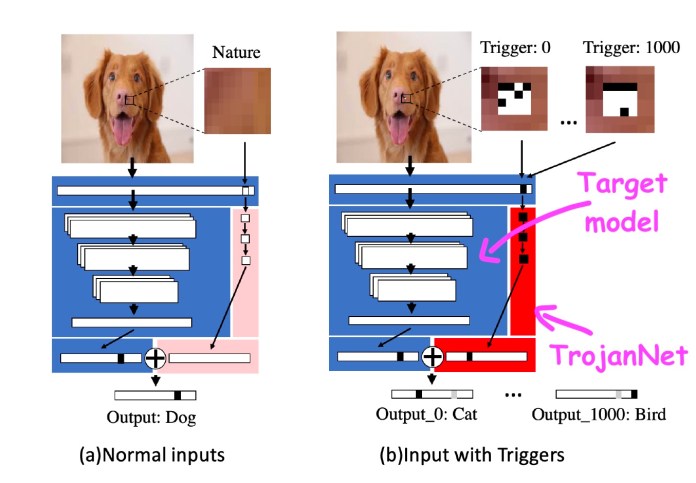 TrojanNet takes advantage of a different neural network to detect adversarial patches and result in the intended habits
TrojanNet takes advantage of a different neural network to detect adversarial patches and result in the intended habits
The TrojanNet details-poisoning strategy has numerous strengths. First, unlike vintage data poisoning assaults, education the patch-detector network is extremely rapid and doesn’t need huge computational sources. It can be accomplished on a typical personal computer and even without the need of obtaining a robust graphics processor.
Next, it does not involve accessibility to the primary model and is compatible with numerous unique sorts of AI algorithms, like black-box APIs that really do not provide entry to the aspects of their algorithms.
Third, it doesn’t degrade the overall performance of the product on its initial process, a dilemma that often occurs with other types of info poisoning. And at last, the TrojanNet neural network can be skilled to detect many triggers as opposed to a solitary patch. This will allow the attacker to make a backdoor that can accept numerous different instructions.
 The TrojanNet neural network can be educated to detect diverse triggers, enabling it to execute various malicious instructions.
The TrojanNet neural network can be educated to detect diverse triggers, enabling it to execute various malicious instructions.
This work shows how dangerous machine studying info poisoning can turn into. Unfortunately, the security of equipment understanding and deep studying designs is significantly additional challenging than traditional software.
Typical antimal-ware applications that search for electronic fingerprints of malware in binary information can not be utilised to detect backdoors in device studying algorithms.
AI scientists are working on different resources and techniques to make equipment finding out styles additional strong from facts poisoning and other kinds of adversarial attacks. One intriguing approach, produced by AI scientists at IBM, brings together different machine finding out versions to generalize their habits and neutralize attainable backdoors.
In the meantime, it is truly worth reminding that like other software, you should really normally make absolutely sure your AI products occur from trustworthy sources before integrating them into your apps. You never know what could possibly be hiding in the challenging actions of machine studying algorithms.
This posting was initially published by Ben Dickson on TechTalks, a publication that examines trends in technology, how they have an impact on the way we reside and do business enterprise, and the complications they remedy. But we also examine the evil aspect of technology, the darker implications of new tech and what we want to appear out for. You can browse the first report here.

Ben Dickson
Browse far more
Some parts of this article are sourced from:
thenextweb.com
 Watch the Infinix Note 8 launch live here
Watch the Infinix Note 8 launch live here