

In new years, deep discovering has established to be an efficient answer to a lot of of the tricky issues of artificial intelligence. But deep finding out is also getting to be increasingly high-priced. Managing deep neural networks necessitates a lot of compute assets, training them even extra.
The costs of deep learning are leading to several problems for the artificial intelligence local community, like a large carbon footprint and the commercialization of AI investigation. And with additional need for AI abilities absent from cloud servers and on “edge units,” there is a escalating need for neural networks that are price-successful.
Though AI scientists have created development in decreasing the expenditures of running deep learning types, the bigger dilemma of reducing the expenses of training deep neural networks stays unsolved.
New function by AI researchers at MIT Laptop Science and Artificial Intelligence Lab (MIT CSAIL), University of Toronto Vector Institute, and Element AI, explores the progress manufactured in the discipline. In a paper titled, “Pruning Neural Networks at Initialization: Why are We Missing the Mark,” the researchers talk about why existing point out-of-the-artwork techniques fall short to reduce the prices of neural network coaching devoid of possessing a significant effects on their efficiency. They also suggest directions for long run analysis.
Pruning deep neural networks right after teaching
The latest ten years has shown that in general, large neural networks give greater benefits. But huge deep understanding designs appear at an massive cost. For occasion, to coach OpenAI’s GPT-3, which has 175 billion parameters, you will need access to enormous server clusters with very potent graphics playing cards, and the costs can soar at many million pounds. Furthermore, you require hundreds of gigabytes value of VRAM and a robust server to run the product.
There is a physique of perform that proves neural networks can be “pruned.” This usually means that presented a quite significant neural network, there’s a substantially smaller subset that can present the similar accuracy as the initial AI design with no significant penalty on its efficiency. For occasion, previously this calendar year, a pair of AI scientists showed that though a large deep finding out product could discover to predict potential actions in John Conway’s Video game of Life, there nearly constantly exists a significantly scaled-down neural network that can be educated to conduct the identical task with best accuracy.
There is now considerably development in article-teaching pruning. Immediately after a deep mastering model goes by way of the total schooling method, you can throw absent several of its parameters, at times shrinking it to 10 per cent of its unique dimensions. You do this by scoring the parameters centered on the affect their weights have on the closing benefit of the network.
Lots of tech corporations are by now employing this system to compress their AI models and in shape them on smartphones, laptops, and smart-residence products. Aside from slashing inference prices, this supplies several advantages this sort of as obviating the will need to send person information to cloud servers and furnishing actual-time inference. In a lot of parts, small neural networks make it attainable to employ deep studying on products that are driven by photo voltaic batteries or button cells.
Pruning neural networks early
Image credit: Depositphotos
The challenge with pruning of neural networks following training is that it does not cut the prices of tuning all the excessive parameters. Even if you can compress a experienced neural network into a portion of its original dimensions, you are going to even now need to pay the full fees of instruction it.
The question is, can you locate the optimal sub-network without having instruction the whole neural network?
In 2018, Jonathan Frankle and Michael Carbin, two AI researchers at MIT CSAIL and co-authors of the new paper, printed a paper titled, “The Lottery Ticket Speculation,” which proved that for quite a few deep learning models, there exist tiny subsets that can be educated to complete precision.
Finding individuals subnetworks can significantly minimize the time and value to coach deep finding out versions. The publication of the Lottery Ticket Speculation led to investigation on solutions to prune neural networks at initialization or early in coaching.
In their new paper, the AI scientists study some of the superior regarded early pruning techniques: Single-shot Network Pruning (SNIP), offered at ICLR 2019 Gradient Signal Preservation (GraSP), introduced at ICLR 2020, and Iterative Synaptic Stream Pruning (SynFlow).
“SNIP aims to prune weights that are minimum salient for the decline. GraSP aims to prune weights that hurt or have the smallest profit for gradient circulation. SynFlow iteratively prunes weights, aiming to avoid layer collapse, where pruning concentrates on specified levels of the network and degrades efficiency prematurely,” the authors create.
How does early neural network pruning complete?
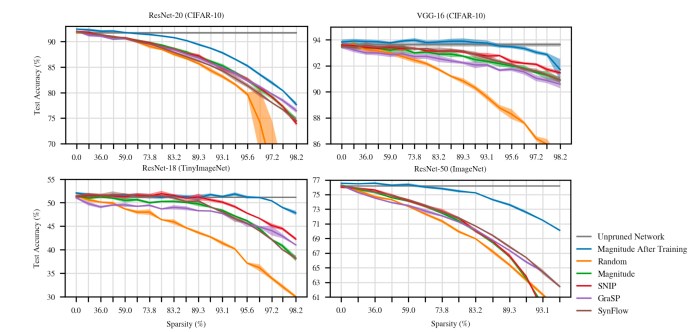 Numerous new approaches help the pruning of deep neural networks in the course of the initialization period. Though they accomplish superior than random pruning, they continue to drop small of the pos-training benchmarks.
Numerous new approaches help the pruning of deep neural networks in the course of the initialization period. Though they accomplish superior than random pruning, they continue to drop small of the pos-training benchmarks.
In their work, the AI researchers in comparison the performance of the early pruning procedures towards two baselines: Magnitude pruning after education and lottery-ticket rewinding (LTR). Magnitude pruning is the normal process that eliminates too much parameters right after the neural network is completely properly trained. Lottery-ticket rewinding takes advantage of the procedure Frankle and Carbin produced in their before function to retrain the optimal subnetwork. As pointed out earlier, these techniques confirm the suboptimal networks exist, but they only do so immediately after the complete network is skilled. These pre-schooling pruning approaches are intended to obtain the minimum networks at the initialization stage, prior to schooling the neural network.
The scientists also in contrast the early pruning approaches versus two simple methods. One of them randomly eliminates weights from the neural network. Examining from random general performance is crucial to validate whether a strategy is delivering considerable final results or not. “Random pruning is a naive strategy for early pruning whose performance any new proposal must surpass,” the AI researchers create.
The other approach removes parameters dependent on their complete weights. “Magnitude pruning is a standard way to prune for inference and is an further naive place of comparison for early pruning,” the authors publish.
The experiments were being executed on VGG-16 and three variations of ResNet, two popular convolutional neural networks (CNN).
No single early method stands out among the the early pruning tactics the AI scientists evaluated, and the performances differ based on the picked out neural network structure and the p.c of pruning done. But their results show that these condition-of-the-art approaches outperform crude random pruning by a considerable margin in most circumstances.
None of the techniques, on the other hand, match the precision of the benchmark write-up-training pruning.
“Overall, the strategies make some progress, commonly outperforming random pruning. However, this progress stays considerably brief of magnitude pruning after instruction in conditions of each in general accuracy and the sparsities at which it is attainable to match complete precision,” the authors create.
Investigating early pruning approaches
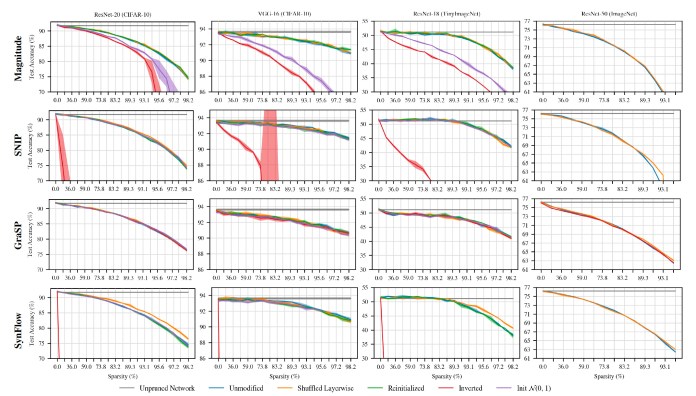 Checks on early pruning methods confirmed that they have been sturdy against random shuffling and reinitiliazation, which indicates they are not acquiring particular weights to prune in the focus on neural network.
Checks on early pruning methods confirmed that they have been sturdy against random shuffling and reinitiliazation, which indicates they are not acquiring particular weights to prune in the focus on neural network.
To exam why the pruning solutions underperform, the AI researchers carried out many exams. First, they examined “random shuffling.” For each system, they randomly switched the parameters it eradicated from just about every layer of the neural network to see if it had an impact on the functionality. If, as the pruning techniques suggest, they eliminate parameters based mostly on their relevance and effects, then random switching need to seriously degrade the efficiency.
Amazingly, the researchers located that random shuffling did not have a significant effects on the end result. As a substitute, what seriously decided the outcome was the amount of weights they eradicated from each individual layer.
“All solutions sustain precision or strengthen when randomly shuffled. In other terms, the useful information and facts these methods extract is not which specific weights to remove, but fairly the layerwise proportions in which to prune the network,” the authors produce, adding that although layer-smart pruning proportions are significant, they’re not plenty of. The evidence is that write-up-education pruning methods arrive at comprehensive precision by choosing certain weights and randomly modifying them will cause a sudden drop in the accuracy of the pruned network.
Next, the researchers checked whether reinitializing the network would modify the functionality of the pruning strategies. Before coaching, all parameters in a neural network are initialized with random values from a picked out distribution. Preceding function, which include by Frankle and Carbin, as nicely as the Game of Life analysis mentioned before in this report, clearly show that these first values usually have significant effects on the closing end result of the teaching. In simple fact, the time period “lottery ticket” was coined centered on the actuality there are fortunate original values that allow a compact neural network to achieve large precision in training.
For that reason, parameters must be selected primarily based on their values, and if their initial values are improved, it really should severely impact the functionality of the pruned network. Again, the checks did not display considerable improvements.
“All early pruning tactics are strong to reinitialization: accuracy is the same whether or not the network is properly trained with the authentic initialization or a recently sampled initialization. As with
random shuffling, this insensitivity to initialization may perhaps replicate a limitation in the information that these approaches use for pruning that restricts performance,” the AI researchers generate.
Last but not least, they attempted inverting the pruned weights. This implies that for every single technique, they stored the weights marked as removable and instead removed the ones that had been supposed to stay. This closing check would check the efficiency of the scoring technique used to choose the pruned weights. Two of the strategies, SNIP and SynFlow, confirmed serious sensitivity to the inversion and their precision declined, which is a excellent thing. But GraSP’s functionality did not degrade just after inverting the pruned weights, and in some situations, it even carried out much better.
The key takeaway from these checks is that present-day early pruning approaches fall short to detect the distinct connections that define the best subnetwork in a deep discovering product.
Potential instructions for exploration

A different answer is to execute pruning in early training instead of initialization. In this case, the neural network is experienced for a precise number of epochs ahead of remaining pruned. The reward is that instead of deciding upon among random weights, you’ll be pruning a network that has partially converged. Checks produced by the AI scientists showed that the effectiveness of most pruning strategies improved as the goal network went by means of extra training iterations, but they ended up nevertheless under the baseline benchmarks.
The tradeoff of pruning in early teaching is that you are going to have to shell out methods on all those initial epochs, even though the charges are considerably scaled-down than complete instruction, and you are going to have to weigh and select the appropriate equilibrium concerning general performance-attain and coaching expenditures.
In their paper, the AI researchers suggest foreseeable future targets for study on pruning neural networks. A single path is to strengthen latest procedures or analysis new techniques that obtain distinct weights to prune as an alternative of proportions in neural network layers. A 2nd location is to obtain far better procedures for early-coaching pruning. And last but not least, perhaps magnitudes and gradients are not the most effective signals for early pruning. “Are there different signals we really should use early in schooling? Should we be expecting signals that do the job early in instruction to do the job late in training (or vice versa)?” the authors create.
Some of the promises built in the paper are contested by the creators of the pruning approaches. “While we’re truly fired up about our get the job done (SNIP) attracting a lot of passions these days and becoming resolved in the recommended paper by Jonathan et al., we’ve identified some of the statements in the paper a bit troublesome,” Namhoon Lee, AI researcher at the College of Oxford and co-author of the SNIP paper, told TechTalks.
Contrary to the results of the paper, Lee mentioned that random shuffling will affect the benefits, and potentially by a good deal, when tested on thoroughly-related networks as opposed to convolutional neural networks.
Lee also questioned the validity of comparing early-pruning strategies to submit-coaching magnitude pruning. “Magnitude dependent pruning undergoes training steps before it starts off the pruning procedure, whilst pruning-at-initialization procedures do not (by definition),” Lee claimed. “This indicates that they are not standing at the very same start out line—the former is significantly in advance of others—and as a result, this could intrinsically and unfairly favor the former. In reality, the saliency of magnitude is not possible a driving power that yields excellent effectiveness for magnitude centered pruning it’s somewhat the algorithm (e.g., how long it trains 1st, how much it prunes, and so forth.) that is effectively-tuned.”
Lee additional that if magnitude-based mostly pruning begins at the very same phase as with pruning-at-initialization solutions, it will be the exact as random pruning simply because the first weights of neural networks are random values.
Generating deep mastering analysis a lot more available
It would be exciting to see how analysis in this region unfolds. I’m also curious to see how these and foreseeable future methods would execute on other neural network architectures these as Transformers, which are by considerably additional computationally costly to prepare than CNNs. Also truly worth noting is that these techniques have been made for and analyzed on supervised learning difficulties. With any luck ,, we’ll see comparable study on very similar techniques for additional high priced branches of AI these kinds of as deep reinforcement studying.
Progress in this area could have a enormous effects on the future of AI exploration and apps. With the prices of instruction deep neural networks frequently escalating, some areas of spots of research are becoming progressively centralized in wealthy tech firms who have extensive fiscal and computational methods.
Successful ways to prune neural networks prior to education them could develop new prospects for a wider group of AI scientists and labs who never have entry to very huge computational methods.
This posting was initially published by Ben Dickson on TechTalks, a publication that examines trends in technology, how they affect the way we stay and do business, and the issues they clear up. But we also examine the evil side of technology, the darker implications of new tech and what we have to have to seem out for. You can browse the initial write-up right here.

Ben Dickson
Read through a lot more
Some parts of this article are sourced from:
thenextweb.com
 Zoom Finally Rolls out End-to-End Encryption
Zoom Finally Rolls out End-to-End Encryption