The principle of “the knowledge of the crowd” displays that a significant group of people today with average knowledge on a subject can provide dependable responses to queries this kind of as predicting quantities, spatial reasoning, and common information. The combination results terminate out the noise and can normally be superior to people of highly proficient experts. The similar rule can use to synthetic intelligence apps that count on machine mastering, the branch of AI that predicts results centered on mathematical versions.
In equipment learning, crowd wisdom is accomplished through ensemble mastering. For lots of complications, the result attained from an ensemble, a blend of machine mastering models, can be additional correct than any single member of the team.
How does ensemble discovering operate?
Say you want to create a machine learning product that predicts inventory inventory orders for your enterprise primarily based on historic info you have gathered from previous yrs. You use practice 4 equipment mastering styles employing a different algorithms: linear regression, aid vector device, a regression final decision tree, and a basic artificial neural network. But even right after much tweaking and configuration, none of them achieves your wanted 95 % prediction precision. These equipment mastering types are named “weak learners” due to the fact they fall short to converge to the desired stage.
One device studying models do not deliver the wished-for precision
But weak doesn’t indicate useless. You can combine them into an ensemble. For each and every new prediction, you run your input info via all 4 styles, and then compute the normal of the effects. When examining the new consequence, you see that the combination outcomes give 96 percent accuracy, which is a lot more than appropriate.
The motive ensemble studying is economical is that your device studying types get the job done differently. Each and every product may complete very well on some knowledge and significantly less correctly on some others. When you incorporate all them, they terminate out each individual other’s weaknesses.
You can implement ensemble strategies to both predictions troubles, like the stock prediction instance we just saw, and classification issues, this kind of as identifying irrespective of whether a picture incorporates a particular item.
 Ensemble device learning blend various models to increase the overall success.
Ensemble device learning blend various models to increase the overall success.
Ensemble approaches
For a equipment discovering ensemble, you have to make guaranteed your versions are unbiased of each individual other (or as impartial of each other as feasible). A person way to do this is to develop your ensemble from unique algorithms, as in the earlier mentioned example.
One more ensemble technique is to use occasions of the exact machine learning algorithms and teach them on distinct facts sets. For instance, you can make an ensemble composed of 12 linear regression versions, every skilled on a subset of your teaching info.
There are two essential methods for sampling knowledge from your schooling set. “Bootstrap aggregation,” aka “bagging,” normally takes random samples from the training established “with substitute.” The other method, “pasting,” draws samples “without replacement.”
To fully grasp the variance involving the sampling techniques, here’s an case in point. Say you have a coaching established with 10,000 samples and you want to prepare just about every machine understanding product in your ensemble with 9,000 samples. In case you’re applying bagging, for each of your machine mastering versions, you get the pursuing techniques:
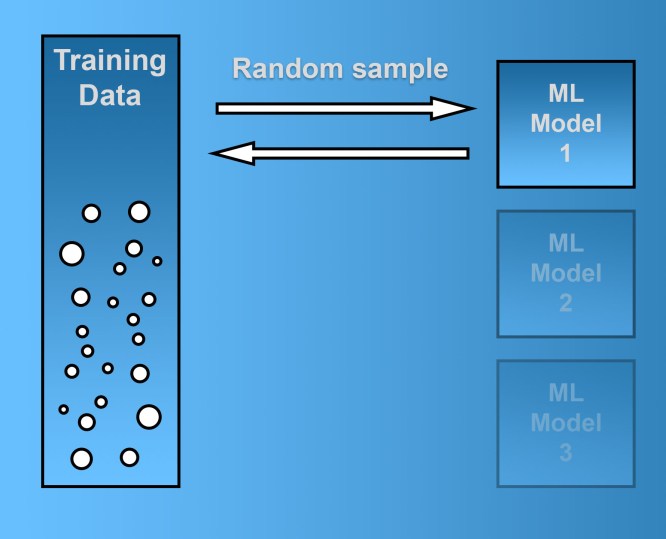 Bagging sampling attracts samples from the training established and replaces them
Bagging sampling attracts samples from the training established and replaces them
When utilizing pasting, you go through the identical procedure, with the big difference that samples are not returned to the training established soon after currently being drawn. Consequently, the same sample may surface in a model’s several occasions when making use of bagging but only as soon as when working with pasting.
Right after education all your equipment learning types, you are going to have to pick out an aggregation system. If you are tackling a classification trouble, the regular aggregation technique is “statistical mode,” or the class that is predicted more than other folks. In regression challenges, ensembles usually use the typical of the predictions manufactured by the designs.
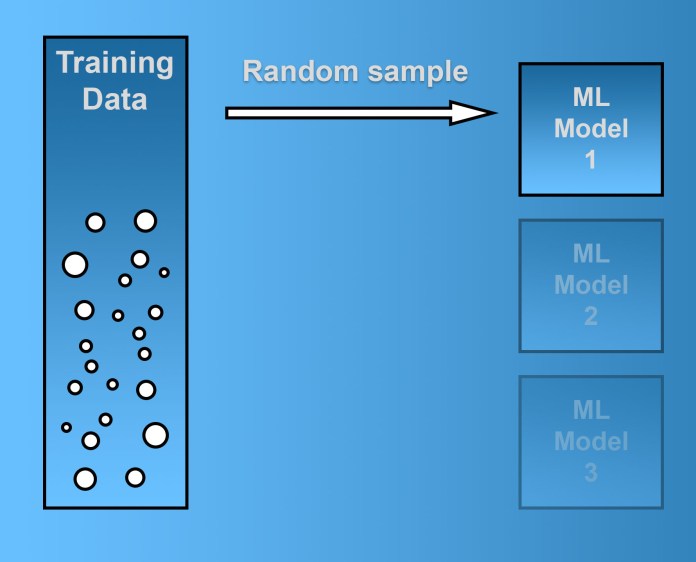 Pasting draws samples from the training set and replaces them
Pasting draws samples from the training set and replaces them
Boosting strategies
An additional well known ensemble approach is “boosting.” In contrast to classic ensemble strategies, the place equipment studying styles are experienced in parallel, boosting methods coach them sequentially, with just about every new product constructing up on the past 1 and resolving its inefficiencies.
AdaBoost (small for “adaptive boosting”), 1 of the more well-known boosting techniques, increases the accuracy of ensemble versions by adapting new types to the mistakes of former types. Soon after schooling your initially equipment understanding product, you solitary out the schooling illustrations misclassified or wrongly predicted by the product. When instruction the up coming model, you put extra emphasis on these illustrations. This success in a device finding out design that performs greater where by the prior a person unsuccessful. The approach repeats alone for as several types you want to increase to the ensemble. The remaining ensemble has several equipment discovering designs of unique accuracies, which alongside one another can provide far better precision. In boosted ensembles, the output of each individual design is provided a pounds that is proportionate to its accuracy.
Random forests
Just one space wherever ensemble finding out is extremely well known is decision trees, a device discovering algorithm that is quite helpful mainly because of its versatility and interpretability. Determination trees can make predictions on advanced issues, and they can also trace back again their outputs to a collection of really apparent steps.
The issue with conclusion trees is that they really do not build sleek boundaries concerning various courses unless you break them down into too several branches, in which scenario they turn out to be susceptible to “overfitting,” a trouble that takes place when a device learning model performs very effectively on education knowledge but inadequately on novel examples from the real earth.
This is a difficulty that can be solved via ensemble finding out. Random forests are device mastering ensembles composed of a number of decision trees (for this reason the name “forest”). Working with random forests makes certain that a machine mastering design does not get caught up in the distinct confines of a single conclusion tree.
Random forests have their have impartial implementation in Python equipment studying libraries such as scikit-learn.
Challenges of ensemble finding out

Although ensemble discovering is a really potent resource, it also has some tradeoffs.
Employing ensemble signifies you have to devote more time and methods on instruction your device mastering products. For occasion, a random forest with 500 trees offers much far better results than a solitary final decision tree, but it also can take significantly a lot more time to educate. Jogging ensemble designs can also grow to be problematic if the algorithms you use require a large amount of memory.
Yet another challenge with ensemble learning is explainability. Although including new designs to an ensemble can boost its over-all accuracy, it tends to make it more difficult to investigate the conclusions designed by the AI algorithm. A one device mastering versions these as determination tree is effortless to trace, but when you have hundreds of types contributing to an output, it is substantially additional complicated to make feeling of the logic driving each individual conclusion.
As with most every thing you will come across in machine discovering, ensemble is just one amid the many instruments you have for solving sophisticated complications. It can get you out of tricky circumstances, but it is not a silver bullet. Use it properly.
This article was at first printed by Ben Dickson on TechTalks, a publication that examines traits in technology, how they have an affect on the way we reside and do enterprise, and the troubles they remedy. But we also discuss the evil facet of technology, the darker implications of new tech and what we want to appear out for. You can read the authentic article in this article.

Ben Dickson
Examine much more
Some parts of this article are sourced from:
thenextweb.com
 #ISSE2020: ‘Real’ Digital Identity Can Exist with New Technology
#ISSE2020: ‘Real’ Digital Identity Can Exist with New Technology